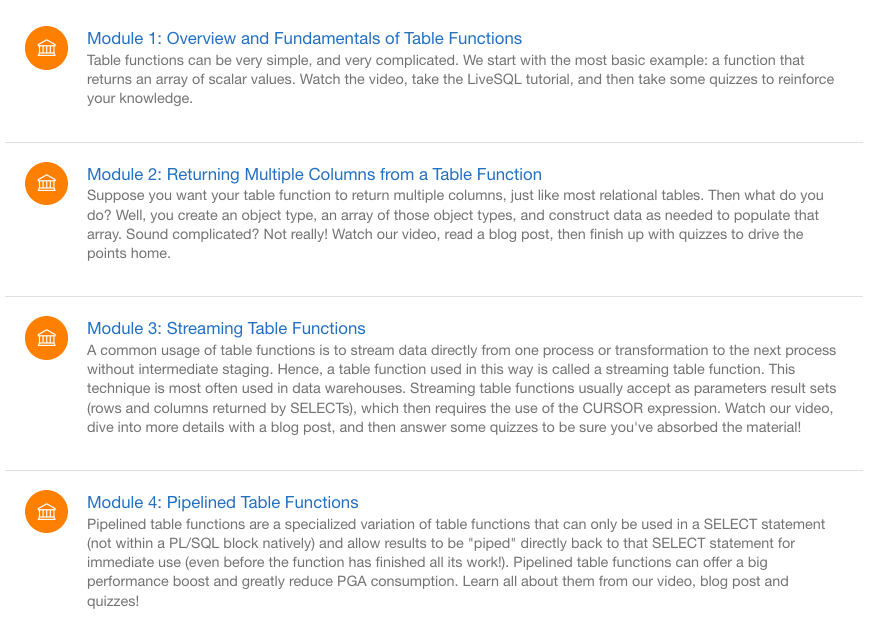
We are using Zoom to host the webcasts for our AskTOM Office Hours program. We schedule the meetings automatically, using their API. We can then also retrieve the meeting information as JSON documents through that same API.
Blaine Carter, the Developer Advocate who did all the heavy lifting around the Zoom API, suggested we take a daily snapshot of all our meetings, so that in case anything goes wrong, we can check back in time, grab the meeting ID, and still get that session going. Great idea!
He also suggested that I use JSON_TABLE to get the job done. Another great idea!
JSON_TABLE, introduced in 12.2, "enables the creation of an inline relational view of JSON content. The JSON_TABLE operator uses a set of JSON path expressions to map content from a JSON document into columns in the view. Once the contents of the JSON document have been exposed as columns, all of the power of SQL can be brought to bear on the content of JSON document." (quoting product manager Mark Drake from his fantastic LiveSQL tutorial on JSON in Oracle Database).
I relied heavily on examples in the doc and the tutorial linked above to get the job done. Here goes.
First, I need to get the structure of the JSON document returned by Zoom. I used the code Blaine had already constructed for me to get all meetings as a JSON document. I then formatted the JSON and found this to work with (IDs and URL changed to protect the innocent):
I then created the relational table:
Then I wrote an INSERT-SELECT, to be executed for each of our two accounts used by Office Hours:
The "$.meetings[*]" path says "Start at the top and find the meetings array.
Each of the path clauses inside COLUMNS indicates the name-value pair to be used for that column. My column names match the JSON key names, but they do not have to.
Then I just tack on the timestamp for when the row was added to the table, put the insert inside a procedure, call the procedure in my daily, overnight job, and wonder of wonder, miracle of miracles, it works!
I hope all the rest of my upcoming efforts at learning and putting to use JSON features of Oracle Database 12.1-12.2 go this smoothly and easily.
Blaine Carter, the Developer Advocate who did all the heavy lifting around the Zoom API, suggested we take a daily snapshot of all our meetings, so that in case anything goes wrong, we can check back in time, grab the meeting ID, and still get that session going. Great idea!
He also suggested that I use JSON_TABLE to get the job done. Another great idea!
JSON_TABLE, introduced in 12.2, "enables the creation of an inline relational view of JSON content. The JSON_TABLE operator uses a set of JSON path expressions to map content from a JSON document into columns in the view. Once the contents of the JSON document have been exposed as columns, all of the power of SQL can be brought to bear on the content of JSON document." (quoting product manager Mark Drake from his fantastic LiveSQL tutorial on JSON in Oracle Database).
I relied heavily on examples in the doc and the tutorial linked above to get the job done. Here goes.
First, I need to get the structure of the JSON document returned by Zoom. I used the code Blaine had already constructed for me to get all meetings as a JSON document. I then formatted the JSON and found this to work with (IDs and URL changed to protect the innocent):
Paste your text here.{
"page_count":2,
"page_number":1,
"page_size":30,
"total_records":35,
"meetings":[
{
"uuid":"c7v0ox8sT8+u33386prZjg==",
"id":465763888,
"host_id":"P6vsOBBd333nEC-X58lE7w",
"topic":"PL/SQL Office Hours",
"type":2,
"start_time":"2018-01-19T17:38:11Z",
"duration":30,
"timezone":"America/Chicago",
"created_at":"2018-01-19T17:38:11Z",
"join_url":"https://oracle.zoom.us/j/111222333"
},
...
{
"uuid":"dn7myRyBTd555t1+2GMsQA==",
"id":389814840,
"host_id":"P6vsOBBd555nEC-X58lE7w",
"topic":"Real Application Clusters Office Hours",
"type":2,
"start_time":"2018-03-28T19:00:00Z",
"duration":60,
"timezone":"UTC",
"created_at":"2018-01-24T16:33:46Z",
"join_url":"https://oracle.zoom.us/j/444555666"
}
]
}
I then created the relational table:
CREATE TABLE dg_zoom_meetings
(
account_name VARCHAR2 (100),
uuid VARCHAR2 (100),
id VARCHAR2 (100),
host_id VARCHAR2 (100),
topic VARCHAR2 (100),
TYPE VARCHAR2 (100),
start_time VARCHAR2 (100),
duration VARCHAR2 (100),
timezone VARCHAR2 (100),
created_at VARCHAR2 (100),
join_url VARCHAR2 (100),
created_on DATE
)
/
Then I wrote an INSERT-SELECT, to be executed for each of our two accounts used by Office Hours:
INSERT INTO dg_zoom_meetings (account_name,
uuid,
id,
host_id,
topic,
TYPE,
start_time,
duration,
timezone,
created_at,
join_url,
created_on)
SELECT account_in,
uuid,
id,
host_id,
topic,
TYPE,
start_time,
duration,
timezone,
created_at,
join_url,
SYSDATE
FROM dual,
JSON_TABLE (dg_zoom_mgr.get_meetings(account_in),'$.meetings[*]'
COLUMNS (
uuid VARCHAR2 ( 100 ) PATH '$.uuid',
id VARCHAR2 ( 100 ) PATH '$.id',
host_id VARCHAR2 ( 100 ) PATH '$.host_id',
topic VARCHAR2 ( 100 ) PATH '$.topic',
type VARCHAR2 ( 100 ) PATH '$.type',
start_time VARCHAR2 ( 100 ) PATH '$.start_time',
duration VARCHAR2 ( 100 ) PATH '$.duration',
timezone VARCHAR2 ( 100 ) PATH '$.timezone',
created_at VARCHAR2 ( 100 ) PATH '$.created_at',
join_url VARCHAR2 ( 100 ) PATH '$.join_url'
)
)
The "$.meetings[*]" path says "Start at the top and find the meetings array.
Each of the path clauses inside COLUMNS indicates the name-value pair to be used for that column. My column names match the JSON key names, but they do not have to.
Then I just tack on the timestamp for when the row was added to the table, put the insert inside a procedure, call the procedure in my daily, overnight job, and wonder of wonder, miracle of miracles, it works!
I hope all the rest of my upcoming efforts at learning and putting to use JSON features of Oracle Database 12.1-12.2 go this smoothly and easily.